
DAP数据分析平台机器学习算法模型说明
当今数据时代背景下更加强调、重视数据的价值,数据是企业生产、经营、战略等几乎所有的经营活动所依赖的、不可或缺的信息,数据是企业的根本,数据包括基础数据、业务数据。
最能体现数据价值的就是进行数据分析,通过DAP数据分析平台的可视化展现,让数据显现差异,观看起来更加顺畅,更加直观,帮助企业有效运营,用数据来指引企业的成长。
整体介绍
DAP数据分析平台更侧重数据的聚合,平台预置有数据源注册、ODS注册与管理、数仓配置与数据聚合,从而实现企业业务数据的统一,构建企业统一的、标准的、完整的数据仓库,为数据展现、数据分析、数据报表,以及外部系统数据交互提供支持。
1.产品方案
首先介绍一下DAP的企业数据中台方案组合框架:
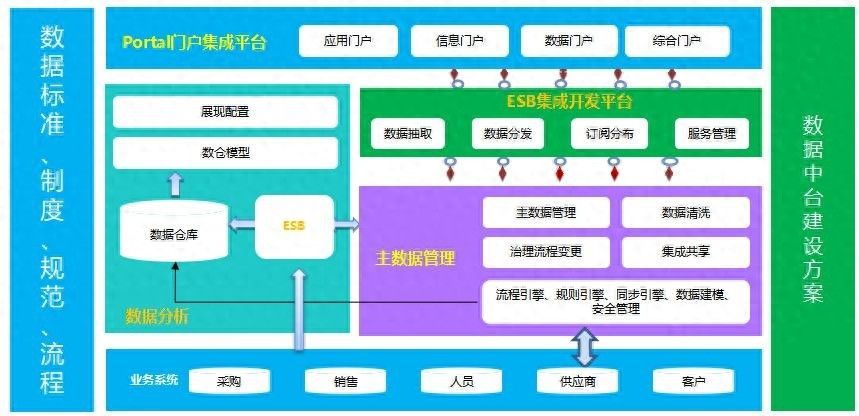
1.DAP数据分析平台:结合ESB从各系统进行数据抽取、加工、转换,并汇聚存储到数仓中,构建企业的大数据中心,基于数仓通过图形化、拖拽式配置构建分析主题,实现快速、精准分析,支持领导层的决策。
2.MDM基础数据平台:对企业中的主数据进行集中管理,统一进行清洗、校验和丰富,建立统一、标准、完整的主数据体系,并为其他系统提供标准的主数据,同时为DAP提供基础数据支持;
3.ESB企业服务总线:从各个系统抽取主数据并同步至MDM平台,支持主数据校验、清洗和汇聚,并配合MDM平台进行主数据分发;,配合DAP平台建立业务数据同步流程,支持数据仓库的建设。
2.产品说明
数据分析平台是一款能够高效存储、计算、分析并处理海量数据的数据分析产品,能够真实、准确、清晰、有效的将企事业内部及行业外部相关数据进行可视化展现,帮助企事业提升行业洞察力,加强决策力,从而提升整体竞争力。

数据分析平台功能有:
1.数据来源(应用系统定义、数据源头配置、ODS数据定义)。
2.数仓模型(业务主题、维度配置、事实配置、模型配置、指标管理)。
3.数据调度(规则校验、调度资源(同步资源、加工资源)、调度任务、调度日志(同步日志、加工日志)、质量日志、通知日志)。
4.分析模型(数据集配置、立方体配置、业务类报表、多维度分析)。
5.展现模型(导航管理、组件管理、展现主题、装饰管理)。
6.数据服务(接收服务、查询服务、统计服务、指标服务、业务服务)。
7.数据标签(标签配置、标签定义、标签画像)。
8.统计分析(数据地图、质量分析、血缘分析、影响分析)。
9.系统管理(组织管理、角色管理、人员管理、功能管理、编码类型、编码管理、系统日志)。
3.功能介绍
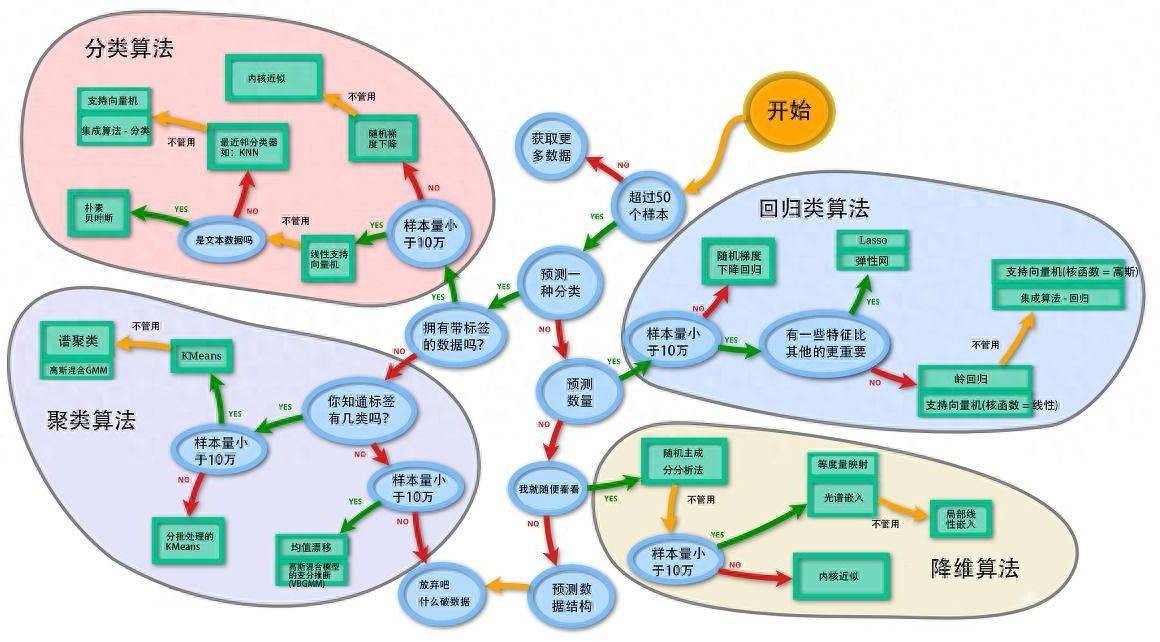
本次机器学习使用Python开源库scikit-learn,通过scikit-learn不同算法模型进行运算从而实现预测分析等,通过不同算法模型来验证训练适合算法,得到最佳方案模型,然后通过DAP数据分析平台分析组件结合模型算出的结果进行预测、预警分析。scikit-learn算法模型主要有回归算法、分类算法、聚类算法、降维算法。
环境搭建
机器学习介绍前首先我们要搭建Python环境,下面进行环境搭建步骤介绍和简单的运行验证。
1.整体说明
通过Conda来搭建Python环境,Conda是一个流行的Python,包括管理器和环境管理器,它可以帮助简化Python环境的搭建和管理过程。
2.安装环境
通过上面的安装包安装步骤进行,就可以安装成功,在地址选项中可以选择自己要安装的位置。
安装完成后我们在下图中能看到安装的环境功能。
选择Anaconda powershell Prompt或者Anaconda Prompt运行。执行下面的命令进行安装:
conda create --name sklearn python=3.9.13。 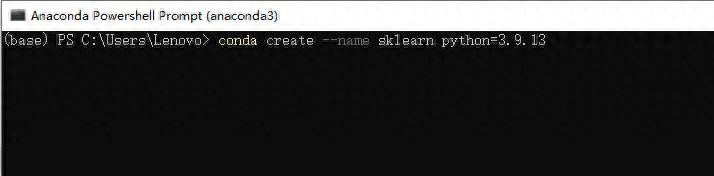
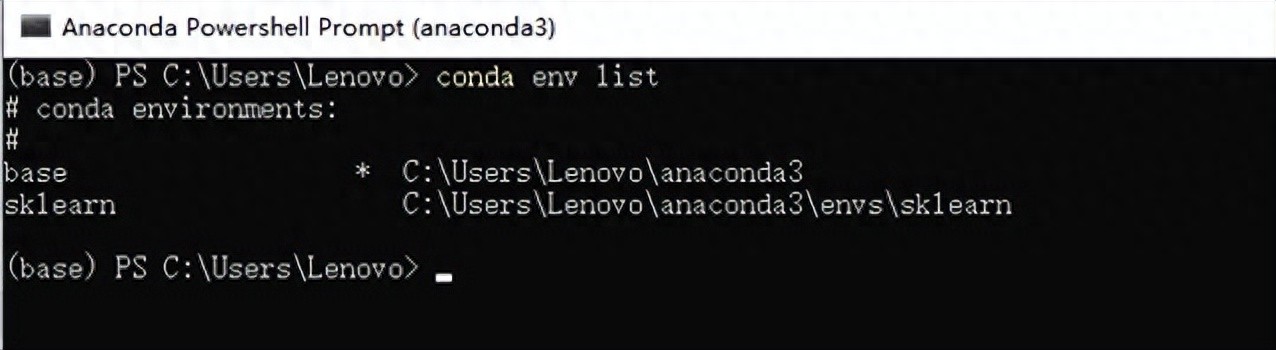
安装完之后安装执行conda activate sklearn,然后执行conda env list验证安装是否成功。如下图就是成功:
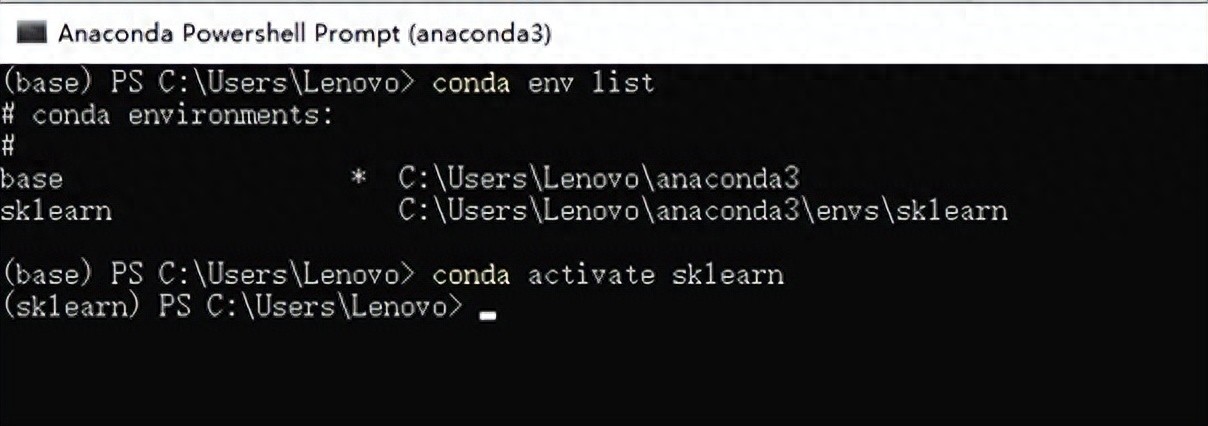
使用conda activate sklearn切换空间。
然后通过PIP在sklearn空间中下载scikit-learn、 ipykernel,命令为:pip install scikit-learn
然后执行python -m ipykernel install --user --name sklearn --display-name "sklearn-kernel"命令。
然后执行pip install pandas、pip install seaborn命令,安装pandas基于Python的数据处理和分析库和基于Python的数据可视化库。
3.开发工具
运行环境有两种:第一种是刚才安装环境自带的 jupyter notebook,直接点击运行即可弹出浏览器运行工具。
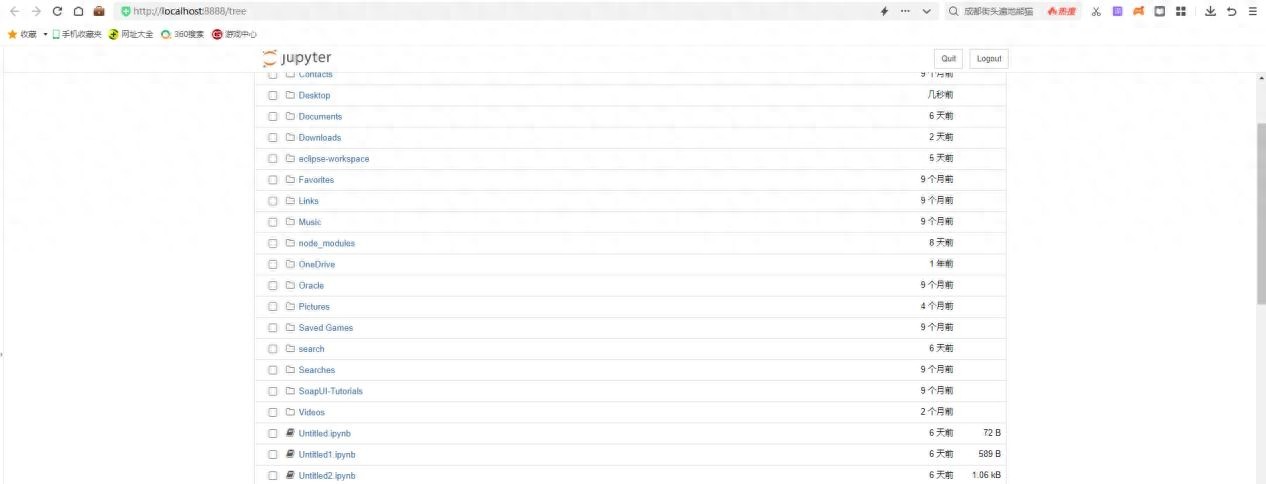
运行工具地址为http://localhost:8888/tree。
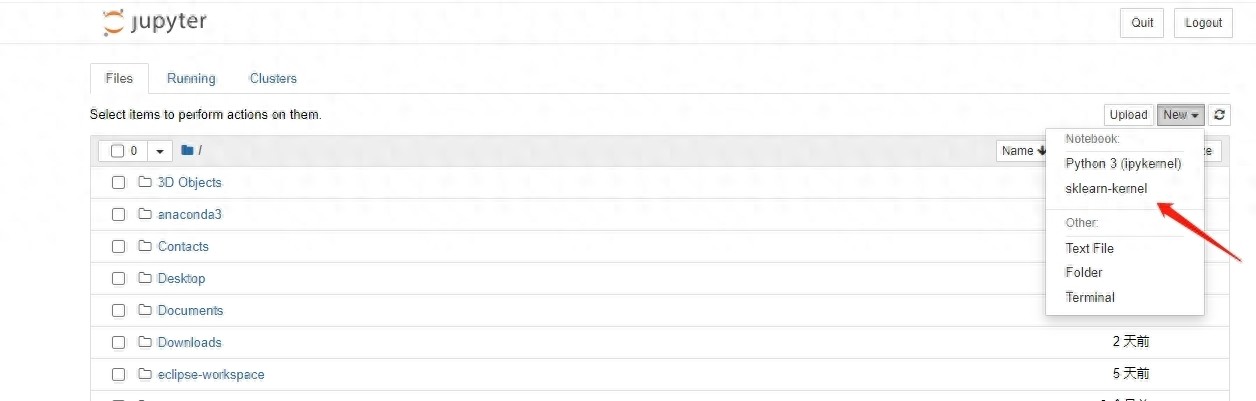
新增一个运行空间,点击scikit-learn进入运行空间中就可以编译Python代码了。
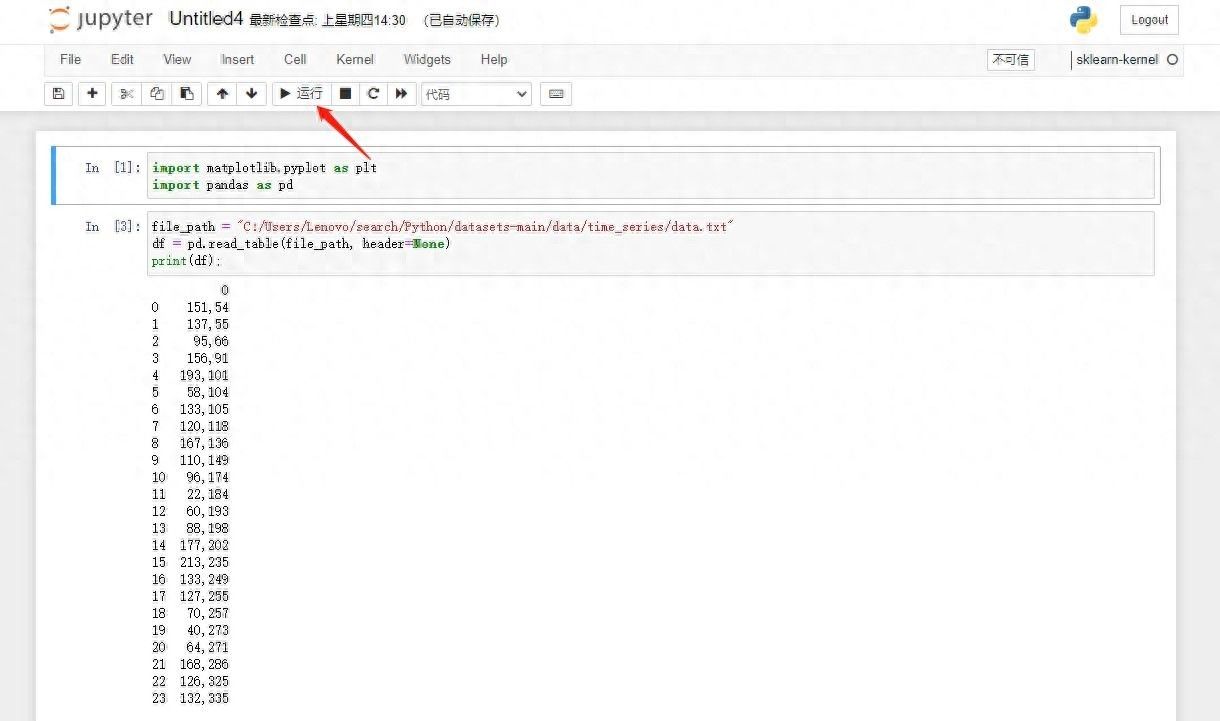
编译完成后点击运行就可以看到执行结果,如下图所示:
第二种是通过Eclipse PyDev来进行运行编译。
算法模型
通过上面安装的环境我们就可以进行算法模型的验证和测试了,首先我们要了解有哪些算法模型,下面就通过模型介绍、模型清单、基本参数来介绍一下算法模型。
1.模型介绍
scikit-learn(简称sklearn)是一个用于机器学习的Python开源库,提供了丰富的工具和函数,用于数据预处理、特征工程、模型选择、模型评估和模型部署等任务。以下是scikit-learn库的一些主要功能和应用,scikit-learn算法模型:回归算法、分类算法、聚类算法、降维算法。
2.模型说明
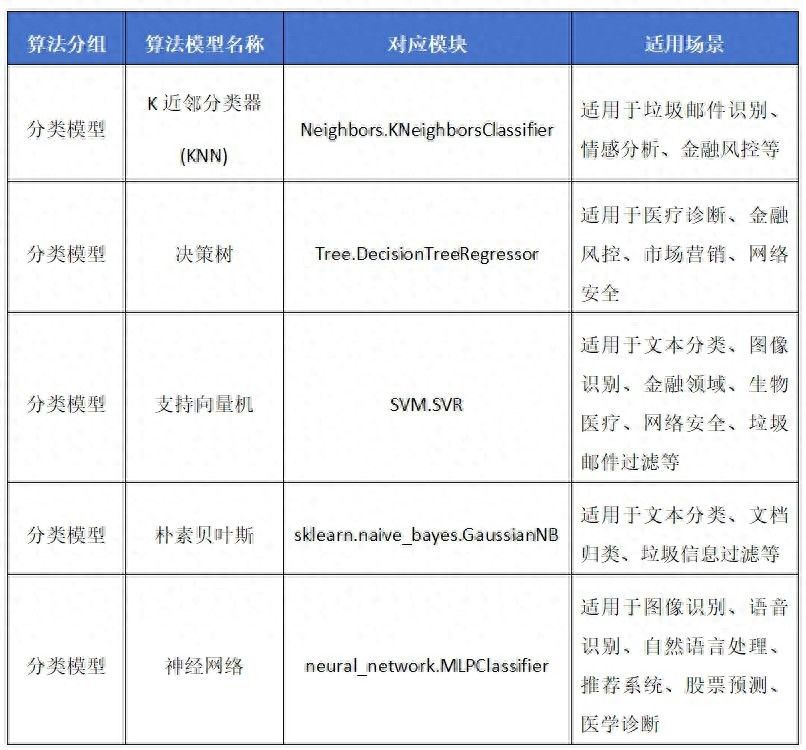
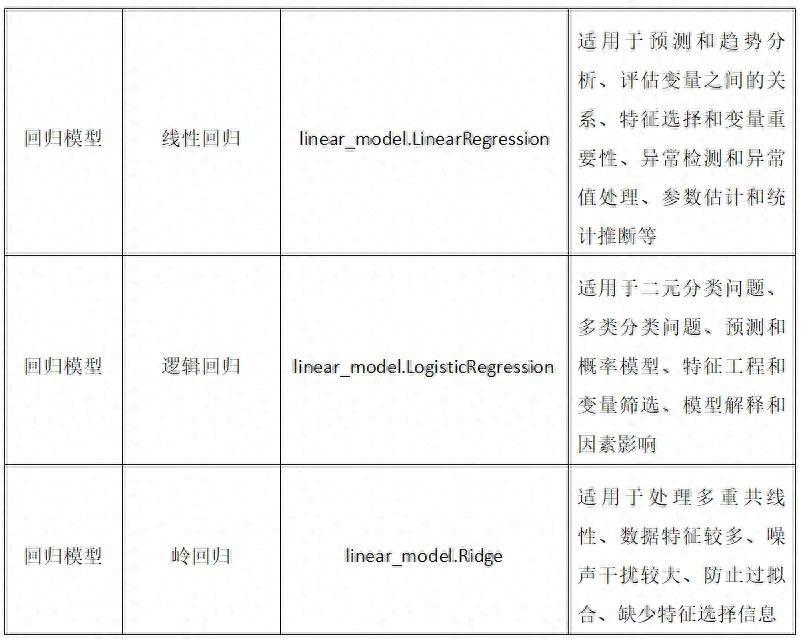
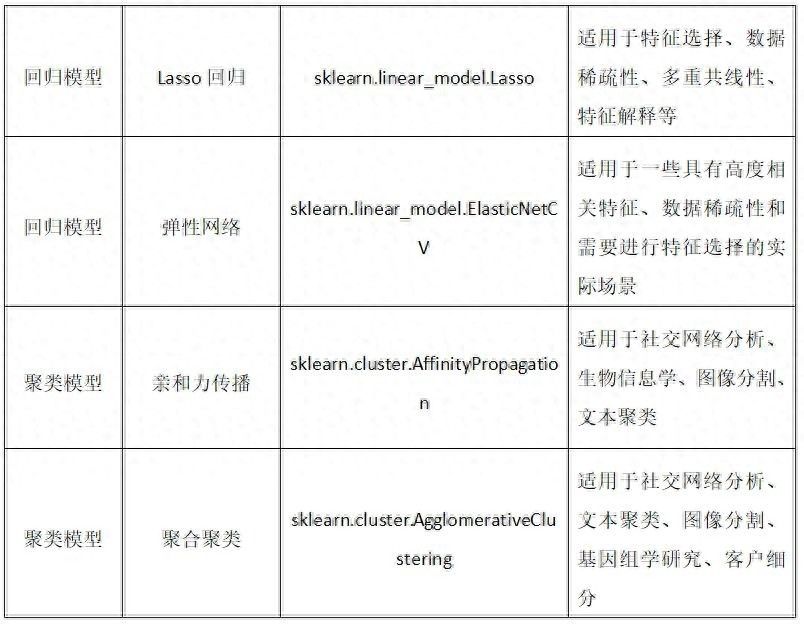
我们常用的算法模型分为四类,分别是分类、回归、聚合、降维。下面是这四类模型名称、对应模块类和适用的场景。
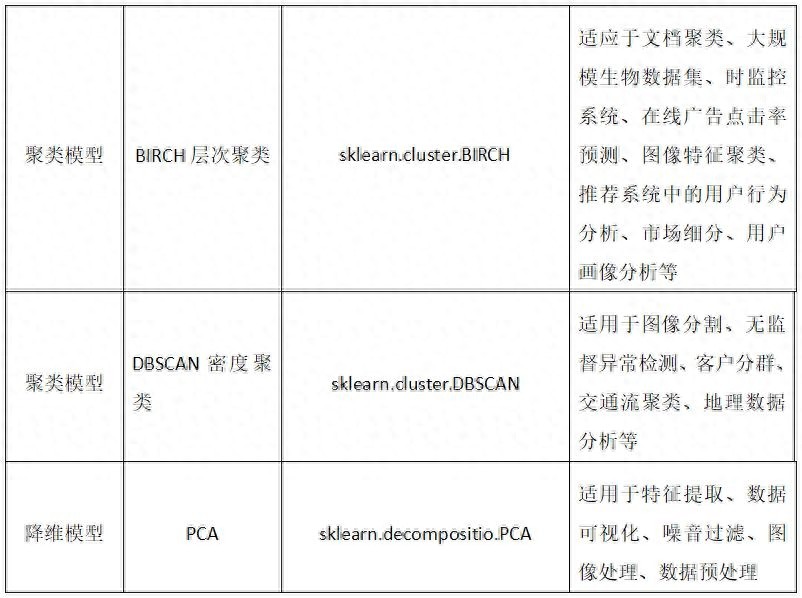
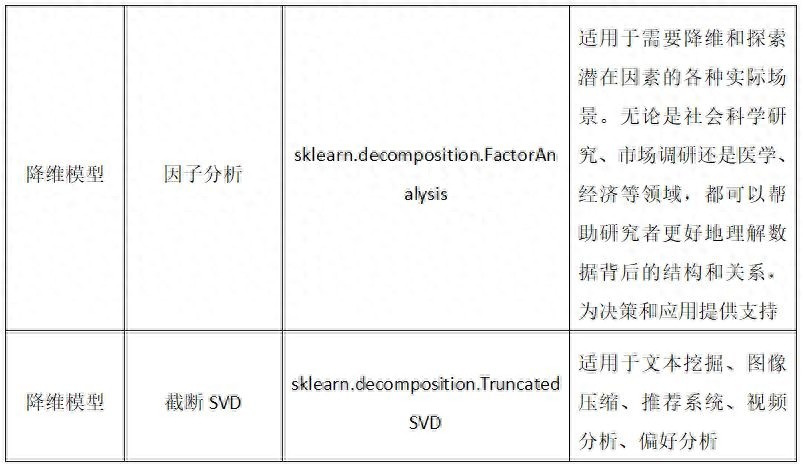
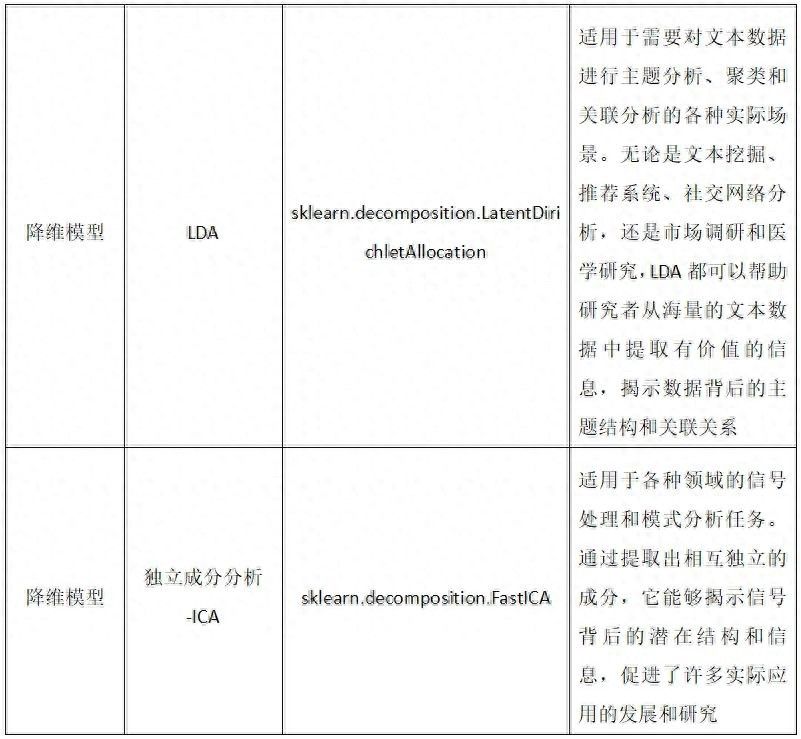
3.算法评估
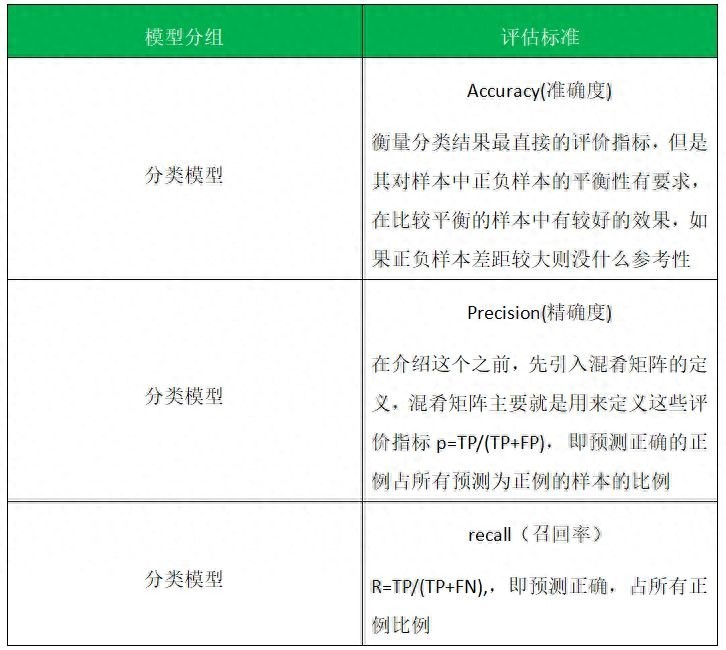
算法模型调用时可以测试数据评估,根据评估标准来有效进行数据分析,下面我会介绍不同类型的评估标准:
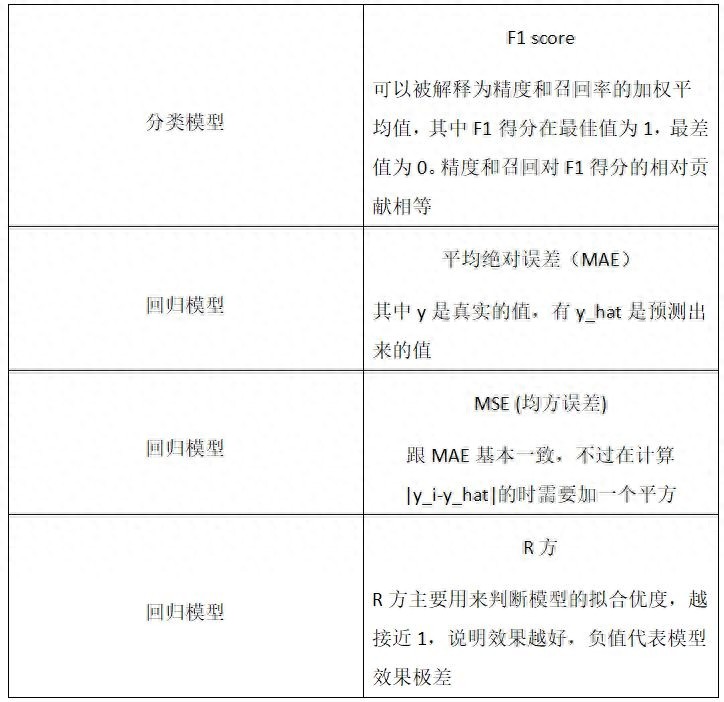
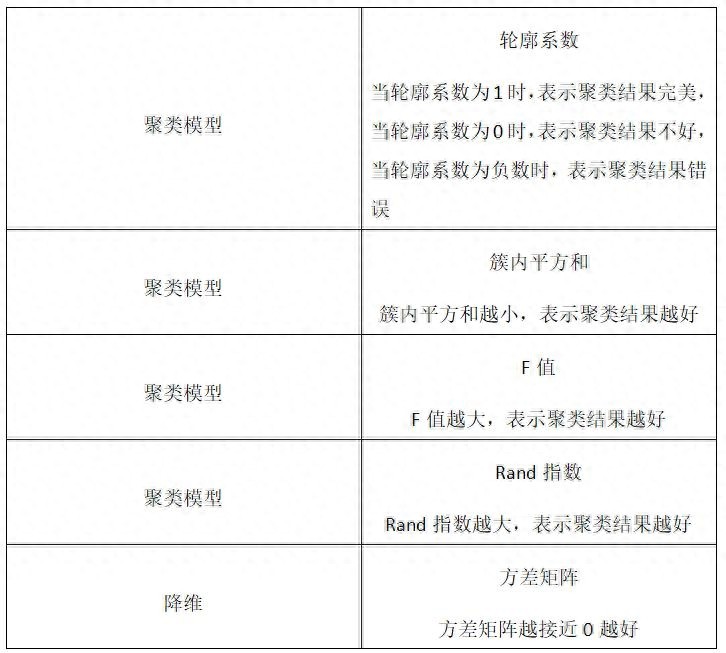
基本参数
四种算法回归、分类、聚合、降维都调用自己的基本参数,下面介绍几种基本参数。
1.回归算法
1.输入特征(Features):回归算法需要指定用于预测的输入特征,这些特征可以是一个或多个变量;
2.输出目标(Target):回归算法需要指定要预测的输出目标,通常是一个连续数值;
3.损失函数(Loss Function):回归算法使用损失函数来度量预测值与实际值之间的差距,常用的损失函数有均方误差(Mean Squared Error)、平均绝对误差(Mean Absolute Error)等;
4.正则化(Regularization):某些回归算法支持正则化参数,如岭回归(Ridge Regression)和Lasso回归(Lasso Regression)。正则化可用于控制模型的复杂度,并避免过拟合;
5.学习率(Learning Rate):对于基于梯度下降的优化算法,学习率决定了每次更新模型参数的步长。较小的学习率可能导致收敛速度变慢,而较大的学习率可能导致不稳定的收敛;
6.迭代次数(Iterations):迭代次数指定了优化算法运行的轮数或步数。更多的迭代次数通常可以使模型更好地拟合训练数据,但过多的迭代可能会导致过拟合;
7.批量大小(Batch Size):对于基于批量梯度下降的优化算法,批量大小确定了每次更新参数时使用的样本数量。较小的批量大小可能导致更大的噪声,而较大的批量大小可能会占用更多的内存;
8.正则化参数(Regularization Parameter):某些回归算法需要调整正则化参数的值,如岭回归中的正则化系数。正则化参数用于平衡模型的拟合能力和泛化能力。
2.分类算法
1.特征选择(Feature Selection):在分类算法中,选择用于训练和预测的特征非常重要。特征选择可以根据一些指标或算法来确定哪些特征能够对分类结果有较好的贡献。常见的特征选择方法包括信息增益、卡方检验、相关系数等。
2.分类器类型(Classifier Type):分类算法有许多不同的分类器类型可供选择,如决策树(Decision Tree)、朴素贝叶斯(Naive Bayes)、支持向量机(Support Vector Machine)、逻辑回归(Logistic Regression)等。不同的分类器具有不同的原理和性能,适用于不同的数据集和问题。
3.正则化参数(Regularization Parameter):某些分类算法,如逻辑回归和支持向量机,可能需要调节正则化参数来平衡模型的复杂度和拟合能力。正则化参数的选择会影响模型的泛化能力和过拟合程度。
4.样本权重(Sample Weights):有时候不同的样本可能具有不同的重要性或代表性,因此可以赋予样本不同的权重来调整分类算法对不同样本的关注程度。样本权重可以用于处理不均衡数据集或调整分类器对错误分类的惩罚程度。
5.阈值设定(Threshold Setting):一些分类算法输出的是概率或置信度,需要设置一个阈值来进行最终的分类决策。根据具体问题和需求,可以通过调整阈值来平衡准确率和召回率之间的权衡。
3.聚合算法
1.装袋法(Bagging):通过从原始训练集中有放回的抽样产生多个子训练集,并对每个子训练集进行独立训练,最终通过投票或平均等方式来决定最终的预测结果,著名的算法包括随机森林(Random Forests)。
2.提升法(Boosting):通过反复训练弱分类器(通常是决策树),并根据前一轮分类器的错误结果调整样本权重,使得后一轮更加关注先前预测错误的样本。预测结果通过加权投票或加权平均得出,常见的算法包括Adaboost和梯度提升树(Gradient Boosting Tree)。
3.堆叠法(Stacking):通过将多个不同类型的基分类器或回归器的预测结果作为新的特征输入到一个元分类器或元回归器中,以得到最终的预测结果。这样可以利用不同算法的优势进行更强大的模型融合
4.降维算法
1.主成分分析(Principal Component Analysis,PCA):
(1)n_components:确定降维后的特征维度数量,可以是具体的数字或保留的信息量比例。
(2)whiten:决定是否对降维后的特征进行白化处理,即使其具有相同的方差。
(3)svd_solver:选择PCA的SVD求解器,可选值有"auto"、"full"、"arpack"和"randomized"等。
2.线性判别分析(Linear Discriminant Analysis,LDA):
(1)n_components:确定降维后的特征维度数量,通常是类别数减1。
(2)solver:选择优化问题的求解器,可选值有"svd"、"lsqr"和"eigen"等。
(3)shrinkage:使用LDA时估计协方差矩阵的收缩方法。
3.t-分布随机邻域嵌入(t-Distributed Stochastic Neighbor Embedding,t-SNE):
(1)n_components:确定降维后的特征维度数量,通常是2或3。
(2)perplexity:控制t-SNE算法的困惑度参数,用于平衡局部和全局结构的保留。
(3)learning_rate:控制学习速率的参数。
4.独立成分分析(Independent Component Analysis,ICA):
(1)n_components:确定输出的独立成分数量。
(2)algorithm:ICA算法的求解器方法,如"fastica"、"picard"等。
(3)max_iter:最大迭代次数。
心得总结
在实际应用中,数据分析可帮助人们做出判断,以便采取适当行动。数据分析是有组织有目的地收集数据、分析数据,使之成为有效信息的过程,有利于提升企业数据的价值。
1.产品作用
随着人们对产品质量的要求越来越高,企业也在尽力提高产品质量水平,以满足市场需求,DAP通过算法模型功能进行指标的预测,从而进行报警策略,让企业第一时间了解生产制造指标的动态,提高生产的质量,这样才能提高利润,企业才能持续发展。
2.产品应用
DAP数据分析机器学习算法模型主要应用在生产制造行业,因为一些设备指标需要算法预测出最佳运行指标,所以需要进行运算,通过DAP数据分析平台算法模型功能配置预置出不同算法模型,然后通过设备采集出的数据进行运算得出结果,进行数据分析,然后定义阈值从而实现报警策略。
3.产品发展
数据中台项目中的难点和重点是各个业务系统的采集,并把数据变成完整的、可观察的数据,从而建立一个标准、可持续应用的数仓,而DAP产品可以把这个过程自动化。
机器学习也是一种基于数据分析的自动化方法,通过算法模型学习数据的模式和规律,从而对未来的数据进行预测和分类,机器学习的未来将会是更加智能化、自主化、高效化的发展趋势。
